

Setting up an evals system for non-engineers, to improve prompts for 10k+ daily conversations by AI-agents
Setting up an evals system for non-engineers, to improve prompts for 10k+ daily conversations by AI-agents
Ankit Sanghvi


At Riverline, our AI-agents speak to 10s of thousands of borrowers each day. Obviously, like most AI-agent systems, initially:
We couldn’t predict and optimize for each edge case in the 1st version of the prompt
We also fear breaking what-was-already-working, each time we update our prompt.
We HAD to manually involve an “engineer” to put a prompt in production to test out against real data to see if it was working. Such a waste of engineering bandwidth, given prompt-testing is something non-technical that just about any person who understands a use-case can do.
For the first 6 months, we used to eyeball this as well and it used to frustrate engineers, and then 1 day at 6am, I realized that it was Independence day so gym wouldn’t open till 7. Hence I deployed the v0 of what is now a system that captures real-data for simulating how prompt will play out against it, what will be its accuracy, and do it all without involving an engineer.
This blog should tell you how we use and setup Braintrust in our code, to ensure we can test and use prompts.
TL;DR
We process tens of thousands of borrower conversations across voice and WhatsApp daily.
Before Braintrust, improving prompts was slow, risky, and required engineers manually shipping every variant.
Now:
Every real interaction flows into Braintrust Logs
We maintain versioned datasets of real calls/messages
We run experiments on new prompts without touching production
Non-engineers can iterate on prompts confidently
We measure accuracy, regressions, and coverage, before shipping
This post explains exactly how we set up Braintrust — Logs → Dataset → Prompt → Experiment — and how to instrument your codebase (TypeScript) so that the whole thing runs on autopilot.
🧠 Why Braintrust?
For AI-agent companies, three truths always hold:
Prompts evolve → new edge cases always appear
Prompts regress → old logic breaks silently
Prompt testing shouldn’t require engineers → PMs/QA teams should be able to iterate
We wanted a system where:
Every real conversation automatically flows into a “ground truth dataset”
Prompts are fully testable offline
Regression KPIs show up before we deploy
Engineering effort remains constant while LLM QA scales to 100k+ interactions/day
Braintrust is perfect for this.
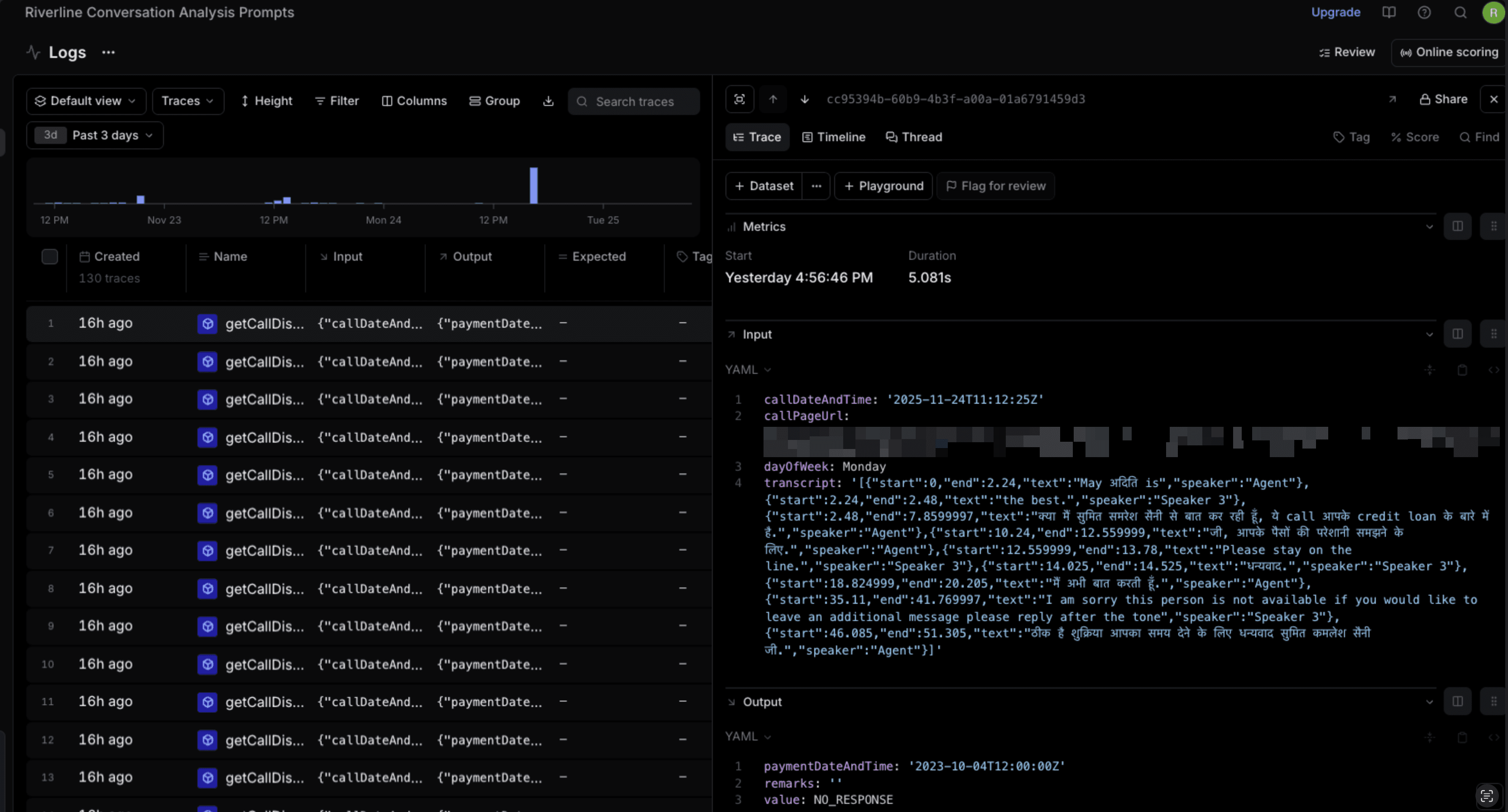
🟣 Step 1 — Stream Real Conversations Into Logs
This is the heart of the setup.
Every time our call-disposition function runs, we log:
Input: callDateAndTime, dayOfWeek, transcript[], callPageUrl
Output: disposition value, remarks, normalized payment datetime
Errors if any
This makes each “LLM execution” appear as a trace inside Braintrust.
We wrapped our existing disposition logic with Braintrust’s initLogger + traced():
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
And now our actual LLM function:
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
This produces logs like:
input.callDateAndTime
input.transcript (JSON array)
output.value (
PTP,NO_RESPONSE, etc.)output.paymentDateAndTime
Braintrust now captures every conversation in a structured format.
🗄 Step 2 — Convert Logs → Datasets
In Braintrust:
Go to Logs
Click “Create Dataset from Logs”
Select the exact trace fields you logged:
input.callDateAndTimeinput.transcriptoutput.valueand whatever else you want to evaluate
You now get a dataset like this:
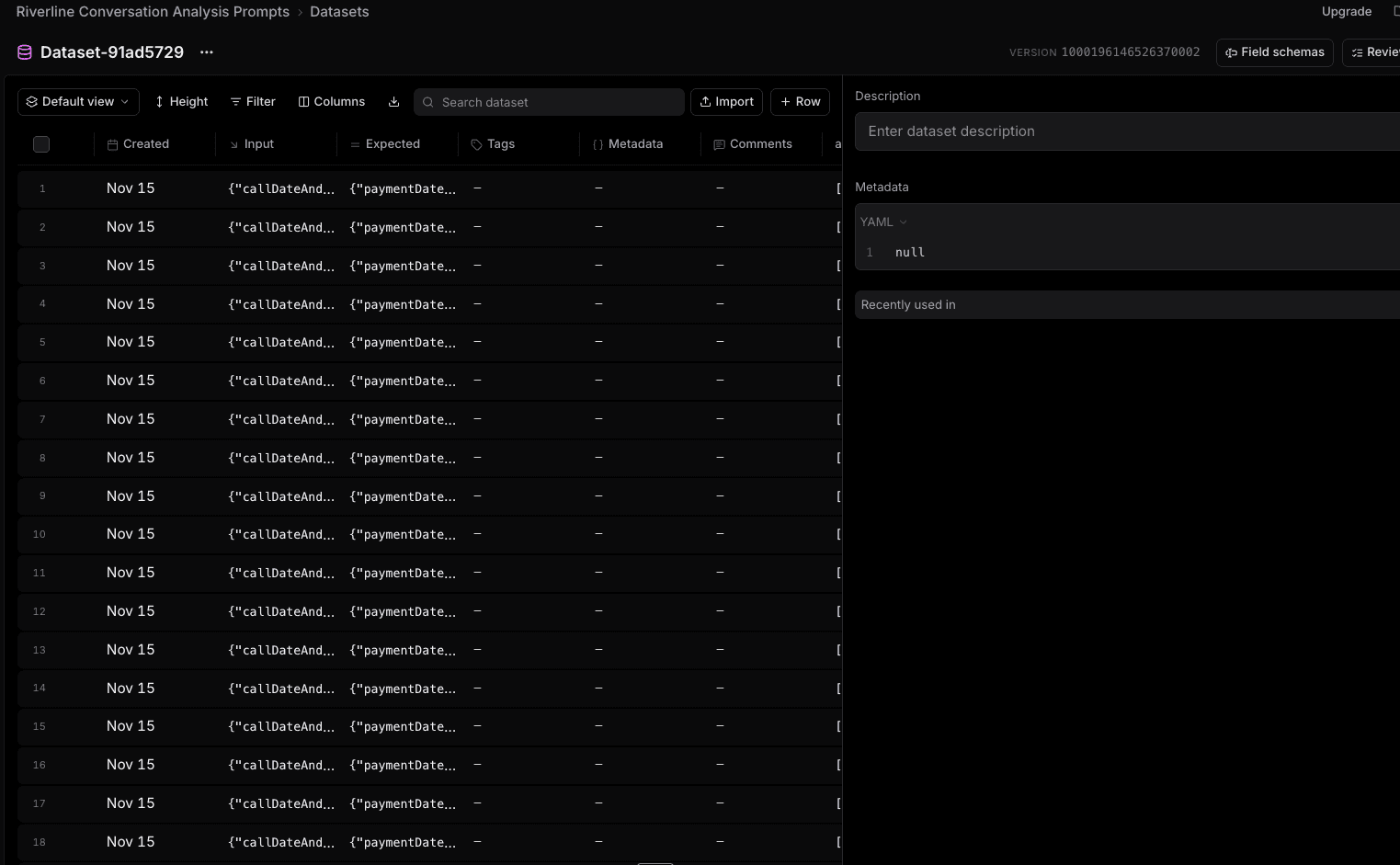
Each row is a real call from production.
Why this matters:
You can now replay prompts on real data without waiting for new calls
You can version datasets (e.g., Nov 15 Batch, Last 3 Days, etc.)
Non-engineers can curate/edit rows without touching code
🧩 Step 3 — Write a Clean, Evaluation-Friendly Prompt
Your production prompt is huge and precise — but in the blog, we won’t reveal it.
The general pattern that works well:
Prompt Structure We Use
Schema first
Force a JSON object
Predefine keys: disposition, remarks, payment datetime
Label definitions + rules
Definitions of PTP / RTP / Callback / Already Paid / NRPC / etc.
Guardrails (explicit refusal required, borrower-initiated required, etc.)
Dominance hierarchy for mixed-signal conversations
Evidence extraction rules
Max 1–2 quotes
Borrower-only quotes
≤ 18 words each
Time normalization rules
“tomorrow morning” → 10:00
“evening” → 18:00
“tonight” → 20:00
Strict validators
PTP must contain commitment + time/amount
Callback must be initiated by borrower
Final JSON only output
No prose, no commentary
Context Variables We Pass
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
The LLM then returns:
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
This makes every experiment reproducible.
🧪 Step 4 — Run Experiments
Braintrust’s experiment runner lets us:
Compare Prompt v1 vs v2 vs v3
Accuracy
Coverage
Row-by-row diff
“Where did this break?”
“Did PTP drop when borrower said ‘tonight’?”
Add evaluation metrics
We define:
Did disposition change?
Is paymentDateTime ISO-formatted?
Did we capture evidence?
Did guardrails pass?
Non-engineers on our team
Now run experiments by just selecting:
Dataset
New prompt
Old prompt
… hit Run.
This is the difference between “prompt tinkering” and “prompt engineering”.
🔁 Step 5 — Iterate Quickly, Deploy Safely
Your workflow now becomes:
PM/QA updates the prompt (no code change)
Run experiment on real dataset (~10k calls)
Review diff → look for regressions
If accuracy ↑ and regressions = 0 → ship to production
Zero developer involvement.
This is how Riverline can ship multiple prompt iterations per week across both voice + WhatsApp agents.
🏗 Full Architecture (High-level)
Flow:
⭐ Tips From Our Journey
1. Always log minimally
Full transcript + call metadata.
No bulky internal objects.
2. Version datasets by date
“Nov 24 batch”, “Past 3 days”
So experiments become repeatable.
3. Add URL back to your system
callPageUrl → helps reviewers inspect the full call UI.
4. Make every failure a logged trace
Don’t hide exceptions.
5. Don’t let prompts sprawl
You’ll be surprised how often a new line breaks 8 categories.
🧵 In closing
With ~20 lines of Braintrust wrapper code, we now run:
Automated prompt regression tests
Dataset-based offline evaluations
Zero-engineer deployment process
High-confidence LLM QA at scale
This setup has easily saved days of engineering hours and dramatically improved prompt coverage across our daily 10k+ conversations.
P.S. If you're an engineer reading this, and this system is something that you'd wanna work on, do apply to our open role at riverline.ai/careers
At Riverline, our AI-agents speak to 10s of thousands of borrowers each day. Obviously, like most AI-agent systems, initially:
We couldn’t predict and optimize for each edge case in the 1st version of the prompt
We also fear breaking what-was-already-working, each time we update our prompt.
We HAD to manually involve an “engineer” to put a prompt in production to test out against real data to see if it was working. Such a waste of engineering bandwidth, given prompt-testing is something non-technical that just about any person who understands a use-case can do.
For the first 6 months, we used to eyeball this as well and it used to frustrate engineers, and then 1 day at 6am, I realized that it was Independence day so gym wouldn’t open till 7. Hence I deployed the v0 of what is now a system that captures real-data for simulating how prompt will play out against it, what will be its accuracy, and do it all without involving an engineer.
This blog should tell you how we use and setup Braintrust in our code, to ensure we can test and use prompts.
TL;DR
We process tens of thousands of borrower conversations across voice and WhatsApp daily.
Before Braintrust, improving prompts was slow, risky, and required engineers manually shipping every variant.
Now:
Every real interaction flows into Braintrust Logs
We maintain versioned datasets of real calls/messages
We run experiments on new prompts without touching production
Non-engineers can iterate on prompts confidently
We measure accuracy, regressions, and coverage, before shipping
This post explains exactly how we set up Braintrust — Logs → Dataset → Prompt → Experiment — and how to instrument your codebase (TypeScript) so that the whole thing runs on autopilot.
🧠 Why Braintrust?
For AI-agent companies, three truths always hold:
Prompts evolve → new edge cases always appear
Prompts regress → old logic breaks silently
Prompt testing shouldn’t require engineers → PMs/QA teams should be able to iterate
We wanted a system where:
Every real conversation automatically flows into a “ground truth dataset”
Prompts are fully testable offline
Regression KPIs show up before we deploy
Engineering effort remains constant while LLM QA scales to 100k+ interactions/day
Braintrust is perfect for this.
🟣 Step 1 — Stream Real Conversations Into Logs
This is the heart of the setup.
Every time our call-disposition function runs, we log:
Input: callDateAndTime, dayOfWeek, transcript[], callPageUrl
Output: disposition value, remarks, normalized payment datetime
Errors if any
This makes each “LLM execution” appear as a trace inside Braintrust.
We wrapped our existing disposition logic with Braintrust’s initLogger + traced():
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
import { initLogger } from "braintrust"; export const llmEvaluationLogger = initLogger({ projectName: BRAINTRUST_PROJECT_NAME, apiKey: BRAINTRUST_API_KEY, asyncFlush: true, // auto flush for long-running processes });
And now our actual LLM function:
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
export const getCallDisposition = async ( params: GetCallDispositionParams, ): Promise<DispositionInfo> => { return await llmEvaluationLogger.traced( async (span) => { const { transcript, callDateAndTime, dayOfWeek, teamId, callCampaignId, callId, } = params; const callPageUrl = teamId && callCampaignId && callId ? `https://app.torrent.riverline.ai/team/${teamId}/campaign/${callCampaignId}/call/${callId}` : undefined; // 1. Log input exactly as we need for datasets/experiments span.log({ input: { callDateAndTime, dayOfWeek, transcript, callPageUrl, }, }); try { const result = await _getCallDisposition(params); // 2. Log output span.log({ output: { value: result.value, remarks: result.remarks, paymentDateAndTime: result.paymentDateAndTime, }, }); return result; } catch (error: any) { span.log({ output: { error: error.message } }); throw error; } }, { name: "getCallDisposition" }, ); };
This produces logs like:
input.callDateAndTime
input.transcript (JSON array)
output.value (
PTP,NO_RESPONSE, etc.)output.paymentDateAndTime
Braintrust now captures every conversation in a structured format.
🗄 Step 2 — Convert Logs → Datasets
In Braintrust:
Go to Logs
Click “Create Dataset from Logs”
Select the exact trace fields you logged:
input.callDateAndTimeinput.transcriptoutput.valueand whatever else you want to evaluate
You now get a dataset like this:
Each row is a real call from production.
Why this matters:
You can now replay prompts on real data without waiting for new calls
You can version datasets (e.g., Nov 15 Batch, Last 3 Days, etc.)
Non-engineers can curate/edit rows without touching code
🧩 Step 3 — Write a Clean, Evaluation-Friendly Prompt
Your production prompt is huge and precise — but in the blog, we won’t reveal it.
The general pattern that works well:
Prompt Structure We Use
Schema first
Force a JSON object
Predefine keys: disposition, remarks, payment datetime
Label definitions + rules
Definitions of PTP / RTP / Callback / Already Paid / NRPC / etc.
Guardrails (explicit refusal required, borrower-initiated required, etc.)
Dominance hierarchy for mixed-signal conversations
Evidence extraction rules
Max 1–2 quotes
Borrower-only quotes
≤ 18 words each
Time normalization rules
“tomorrow morning” → 10:00
“evening” → 18:00
“tonight” → 20:00
Strict validators
PTP must contain commitment + time/amount
Callback must be initiated by borrower
Final JSON only output
No prose, no commentary
Context Variables We Pass
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
Call Date and Time: {{ input.callDateAndTime }} Transcript (JSON array)
The LLM then returns:
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
{ "value": "...", "remarks": "...", "paymentDateAndTime": "..." }
This makes every experiment reproducible.
🧪 Step 4 — Run Experiments
Braintrust’s experiment runner lets us:
Compare Prompt v1 vs v2 vs v3
Accuracy
Coverage
Row-by-row diff
“Where did this break?”
“Did PTP drop when borrower said ‘tonight’?”
Add evaluation metrics
We define:
Did disposition change?
Is paymentDateTime ISO-formatted?
Did we capture evidence?
Did guardrails pass?
Non-engineers on our team
Now run experiments by just selecting:
Dataset
New prompt
Old prompt
… hit Run.
This is the difference between “prompt tinkering” and “prompt engineering”.
🔁 Step 5 — Iterate Quickly, Deploy Safely
Your workflow now becomes:
PM/QA updates the prompt (no code change)
Run experiment on real dataset (~10k calls)
Review diff → look for regressions
If accuracy ↑ and regressions = 0 → ship to production
Zero developer involvement.
This is how Riverline can ship multiple prompt iterations per week across both voice + WhatsApp agents.
🏗 Full Architecture (High-level)
Flow:
⭐ Tips From Our Journey
1. Always log minimally
Full transcript + call metadata.
No bulky internal objects.
2. Version datasets by date
“Nov 24 batch”, “Past 3 days”
So experiments become repeatable.
3. Add URL back to your system
callPageUrl → helps reviewers inspect the full call UI.
4. Make every failure a logged trace
Don’t hide exceptions.
5. Don’t let prompts sprawl
You’ll be surprised how often a new line breaks 8 categories.
🧵 In closing
With ~20 lines of Braintrust wrapper code, we now run:
Automated prompt regression tests
Dataset-based offline evaluations
Zero-engineer deployment process
High-confidence LLM QA at scale
This setup has easily saved days of engineering hours and dramatically improved prompt coverage across our daily 10k+ conversations.
P.S. If you're an engineer reading this, and this system is something that you'd wanna work on, do apply to our open role at riverline.ai/careers