

Improvement Harness for voice agent workflows
Improvement Harness for voice agent workflows
Vedant Shelkar

Riverline handles thousands of debt resolution conversations every day across multiple languages, borrower profiles and fintech portfolios. Each conversation is a voice agent navigating a high-stakes interaction: understanding a borrower's situation, responding to objections, calling the right tools at the right time and reaching a clear outcome.
At thousands of calls a day, you can't listen to everything. Agents break in ways nobody notices. An agent starts repeating itself, a phase transition fails for a specific borrower profile, a change that fixed one scenario quietly breaks another. By the time someone flags it, the pattern has been running across hundreds of conversations. We built a system that finds these problems, generates fixes in prompt and validates them in simulation before they reach production.
System architecture
The system has four layers, each solving a distinct problem:
Layer | Purpose |
|---|---|
Evaluator | Identifies what's going wrong in production |
Improver | Generates targeted agent changes with evidence |
Patcher | Applies scoped edits that preserve what's working |
Harness | Tests fixes in simulation before they ship |
These layers form a closed loop:
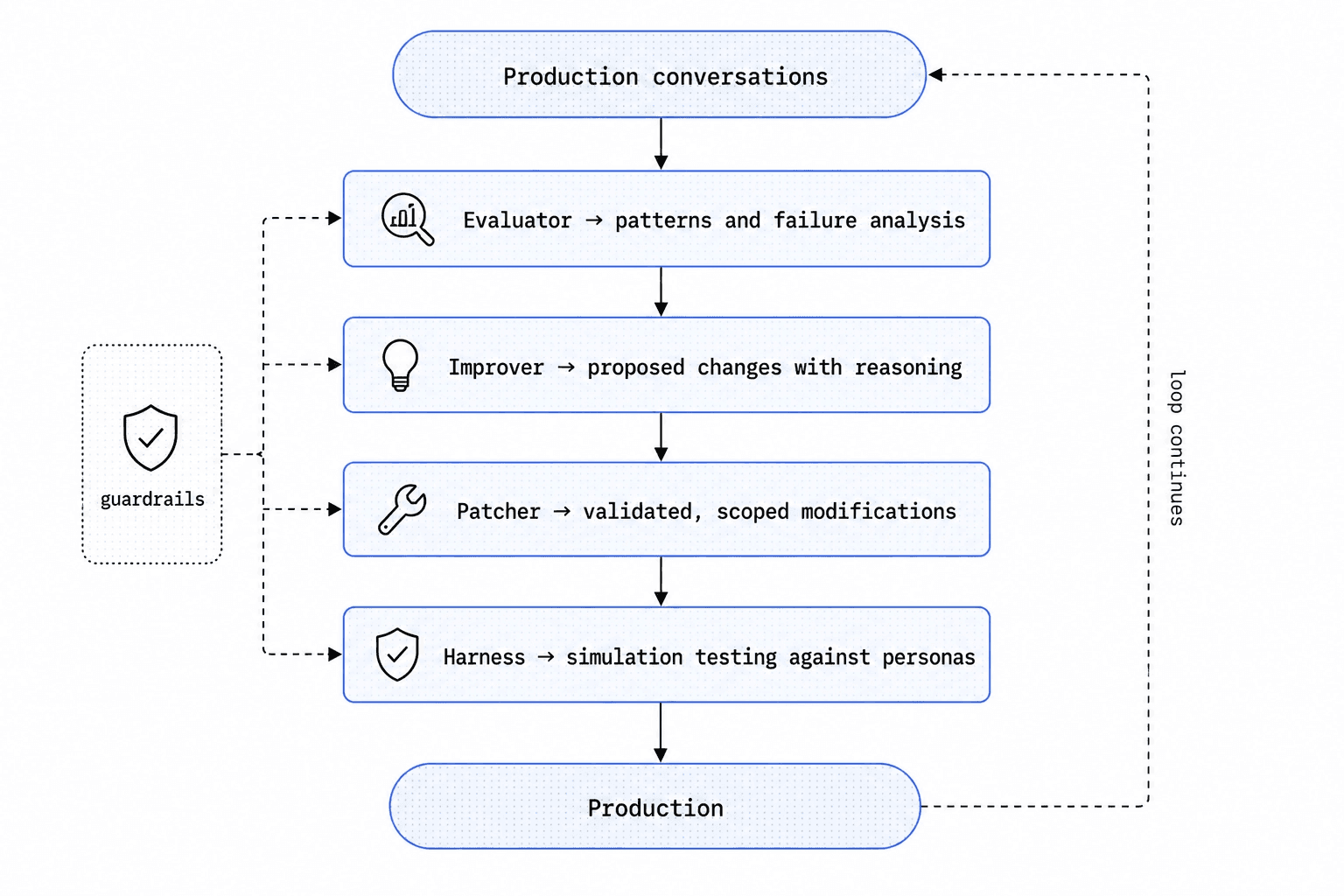
The output of this loop isn't a report or a dashboard. It's a specific, proposed prompt change backed by evidence from production and tested in simulation.
The architecture is progressing towards a self-improving agent-prompt loop: a system that autonomously discovers problems, generates fixes in prompt, validates them and ships improvements continuously. The key constraint is guardrails. Automated improvement without boundaries is dangerous, so every layer in the loop operates within defined safety constraints: the evaluator flags only validated failure patterns, the improver generates changes within scoped boundaries, the patcher enforces preservation rules and the harness gates deployment behind regression thresholds. The goal is not unsupervised autonomy but a system that does the cognitive work at scale while staying grounded in measurable, auditable constraints.
The Evaluator
Most evaluation systems output a score. A score tells you how bad things are but not why. Without the why, you can't generate a fix.
The evaluator produces written analysis. Not numbers. For each transcript, it identifies what went wrong, at which turn and how it affected the rest of the conversation. These per-transcript analyses get consolidated across hundreds of calls to surface systemic patterns rather than one-off mistakes.
The evaluator grades each transcript with reasoning, scoring and evidence. What went wrong, where and how it affected the outcome.
Context-awareness
Not every surface-level issue is a real failure. The evaluator has to distinguish genuine problems from appropriate agent behaviour given the conversational context. Otherwise it generates fixes for things that aren't broken.
———
Tuning the judge
Most evaluation datasets are imbalanced. It passes heavily outnumber failures. This makes raw accuracy misleading. A judge that defaults to "pass" on every transcript might hit 95% accuracy while catching zero actual problems.
An evaluator is only useful if its judgments are trustworthy. If the judge says a call failed when it didn't. Or worse, says it passed when it didn't Every downstream decision is wrong. False improvements are more dangerous than no improvements. You ship a change, the judge says it helped, but the actual conversations got worse.
This is why the evaluator itself has to be evaluated Against human judgment.
True Positive Rate (TPR): How well does the judge correctly identify the failures?
True Negative Rate (TNR): How well does the judge correctly identify the passes?
The goal is to achieve high scores on both TPR and TNR. This confirms the judge is effective at finding real problems without being overly critical. This measurement process uses a standard dataset split mentioned below.
Ground truth
The foundation is a golden dataset: a set of transcripts where humans have annotated what actually happened. Did the agent repeat itself unprompted, or was it responding to a legitimate re-ask? Did the call reach a conclusive outcome, or did it drift? These human labels become the source of truth that the judge is measured against.
Building this dataset is deliberate. You start small: annotate a few hundred transcripts across the failure modes you care about, and expand as the system matures.
Dataset splits
The golden dataset serves three distinct purposes, so it gets split accordingly:
Split | Size | Purpose |
|---|---|---|
Fewshots | ~20% | Teach the judge: these examples are embedded as in-context learning for the evaluator |
Validation | ~40% | Iterate and improve: compare judge output against human labels, find disagreements, refine |
Test | ~40% | Final check: held out to verify the judge isn't overfitting to the validation set |
The fewshot split teaches the judge what good and bad looks like. The validation split is where the real work happens: you run the judge, compare its labels against the human annotations and identify where it disagrees. The test split is the honest check at the end.
Aligning the judge
The judge gets measured the same way you'd measure any classifier: precision and recall, tracked against human annotations.
A judge that always says "pass" might look accurate when failures are rare, but it will never surface a single problem. Tracking these metrics against the golden dataset ensures the judge is genuinely aligned with human assessment, not just statistically accurate on an imbalanced distribution.
The tuning cycle: run the judge on the validation set → compare against human labels → identify disagreement patterns → refine the evaluator → re-run. This continues until the judge's precision and recall are stable across the test set.
The entire improvement pipeline downstream (the improver, the patcher, simulation testing) depends on the evaluator's findings being real. If the judge is miscalibrated, every fix it generates addresses a phantom problem or misses an actual one. Tuning the judge is the prerequisite for everything else.
Better judge → better metrics → better improvements → better conversations → more conclusive calls
————-
The evaluation flywheel
With a tuned judge and ground truth in place, the system operates as a continuous flywheel:
Voice agents at scale feel brittle. A configuration that handles conversations well one week can produce unexpected failures the next. Conversations are sensitive to small changes in borrower behaviour, context and phrasing. To build reliable voice agents, you need a systematic way to make them more resilient.
The solution is a continuous, iterative process: the evaluation flywheel. Instead of guessing what might improve an agent, this provides a structured engineering discipline to diagnose, measure and fix problems.
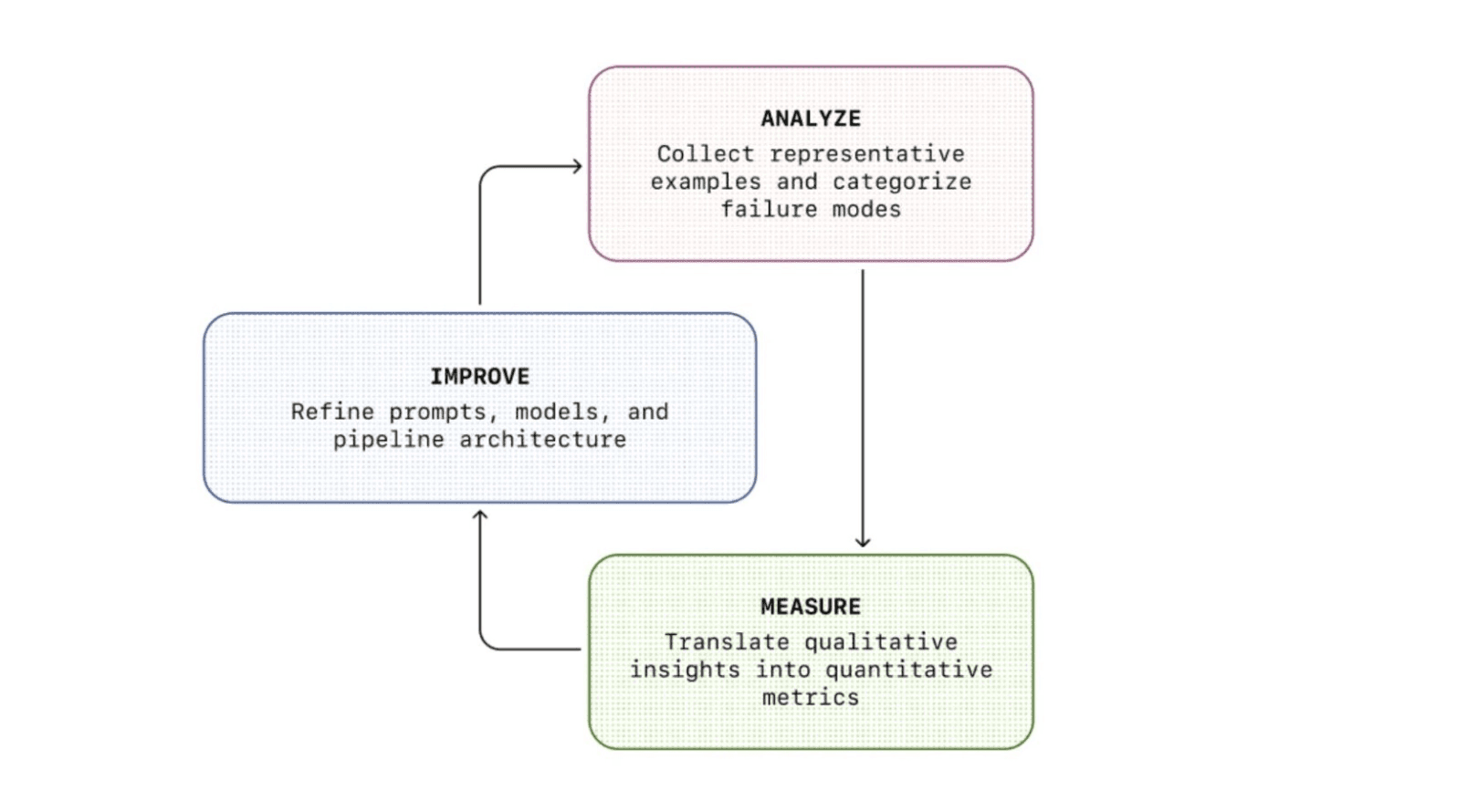
The flywheel consists of three phases:
Analyze: Understand how and why the agent is failing through qualitative review. Examine and annotate transcripts where the agent behaves incorrectly to identify recurring failure modes. The goal is identifying recurring failure patterns, not isolated incidents.
Measure: Turn those qualitative findings into quantifiable metrics. Build a test dataset, define automated graders and establish a baseline. You can't improve what you can't measure.
Improve: Apply targeted fixes, including modifying agent behaviour, restructuring conversation phases, adding edge-case handling. Because measurement is already in place, the impact of each change is visible immediately.
The cycle never finishes and is continuous. Every round of improvements raises the bar, and previously invisible failure modes surface. The agent gets better not through intuition but through compounding, measurable iterations.
The Improver and Patcher
The evaluator's findings feed into two downstream layers. The improver generates targeted modification proposals, each tied to a specific conversation phase and backed by evidence from real calls. The patcher applies those modifications with a key constraint: changes must be scoped and traceable. Not full rewrites, but targeted edits that preserve everything already working. This ensures traceability when something regresses, preservation of configurations earned through months of production and the ability to roll back individual changes without affecting unrelated improvements.
—————
The Harness
Evaluation tells you what went wrong in the past. The harness tells you whether a fix actually helps, before it touches production.
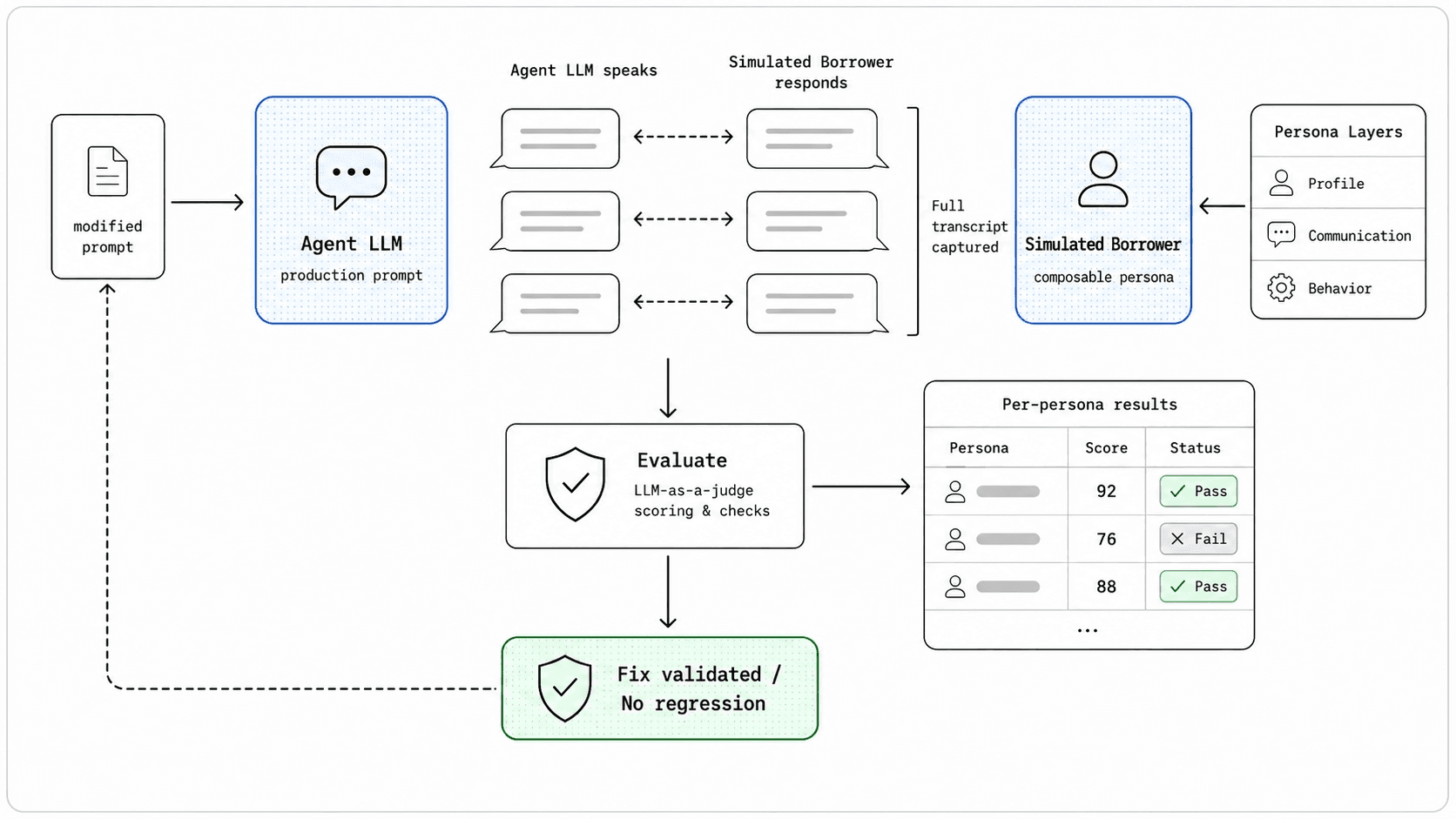
The harness runs LLM-vs-LLM simulations: one LLM plays the agent with the actual agent configuration, another plays a borrower persona.
Composable personas
Scripted test cases don't capture the diversity of real conversations. A persona-based approach does: each simulated borrower is assembled from three independent layers:
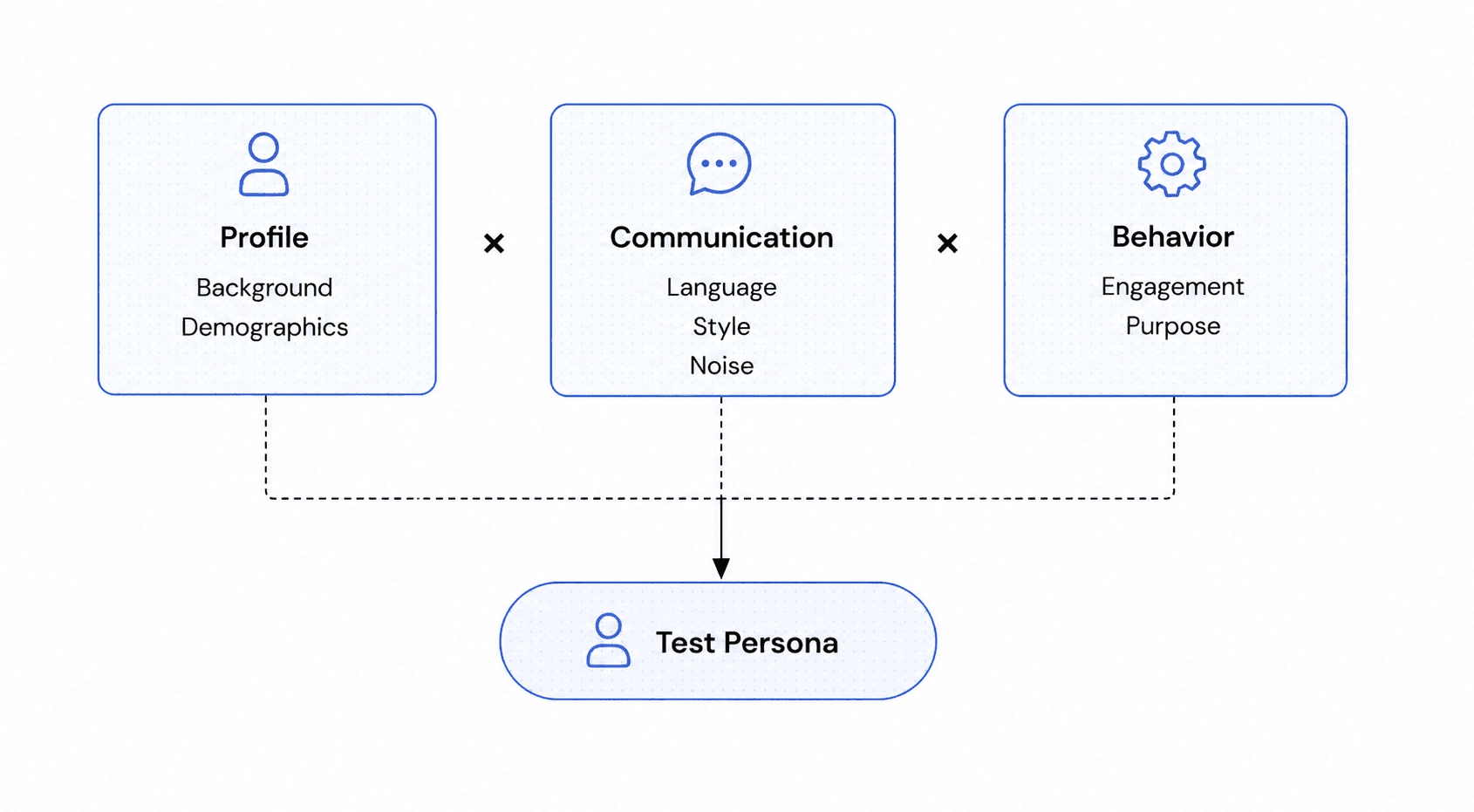
Each layer is independent. Any profile can combine with any communication style and any behaviour pattern. This generates a wide range of realistic test personas from a small number of well-defined traits.
Scaling through composition
The composable approach is what makes this scale. Instead of hand-writing hundreds of test scripts, you define traits per layer and let the combinations multiply:
8 profiles × 6 communication styles × 10 behaviour patterns × 3 languages = 1,440 distinct test personas
This is combinatorial coverage, not brute force. A small number of well-chosen traits per layer generates a large, diverse test surface. And it scales further. Adding one new behaviour pattern creates new test cases across every profile and language without duplicating work.
From small to production scale
You don't start with all 1,440. The system grows progressively, optimising the prompts and improving the voice agent.
The important thing isn't the number; it's that results are tracked per persona, not in aggregate. An agent that scores well on average but consistently fails with evasive Hindi-speaking borrowers has a real problem that aggregate metrics would hide.
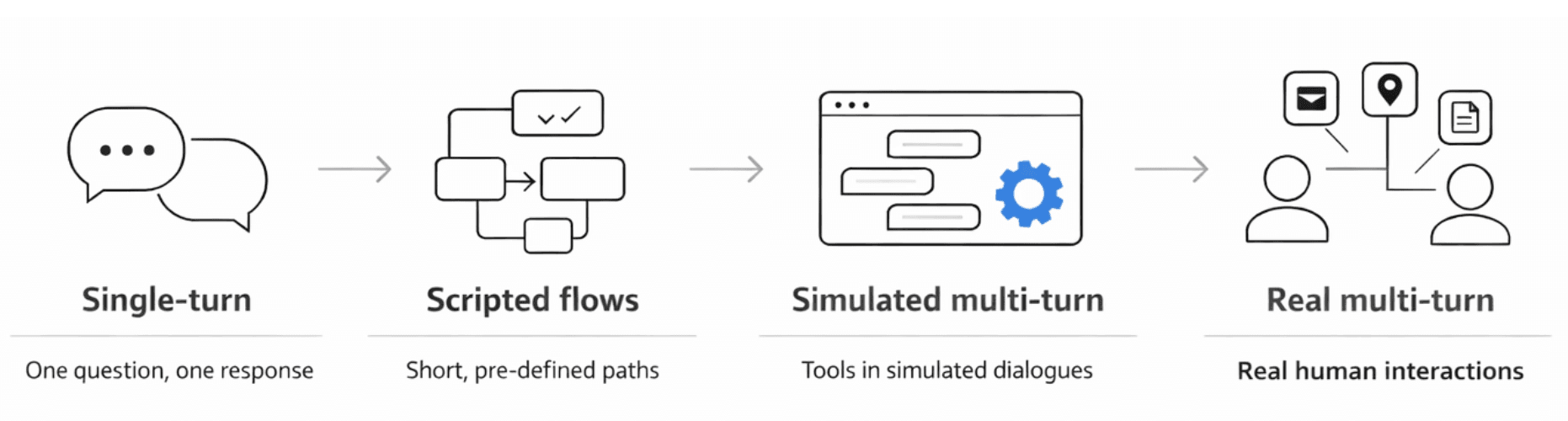
Regression testing
Every agent version must pass through the regression set before it ships. If a modification introduces a new failure, even for a single persona, it gets caught in simulation rather than production. This is a fixed set of personas against which any prompt must be optimised for.
—————
Expanding towards a robust eval system
Everything above is focused on conversation quality – that's where the system operates today. But a voice AI agent is several systems working together, each with its own failure modes. We're expanding the same evaluate-improve-test loop across the full stack.
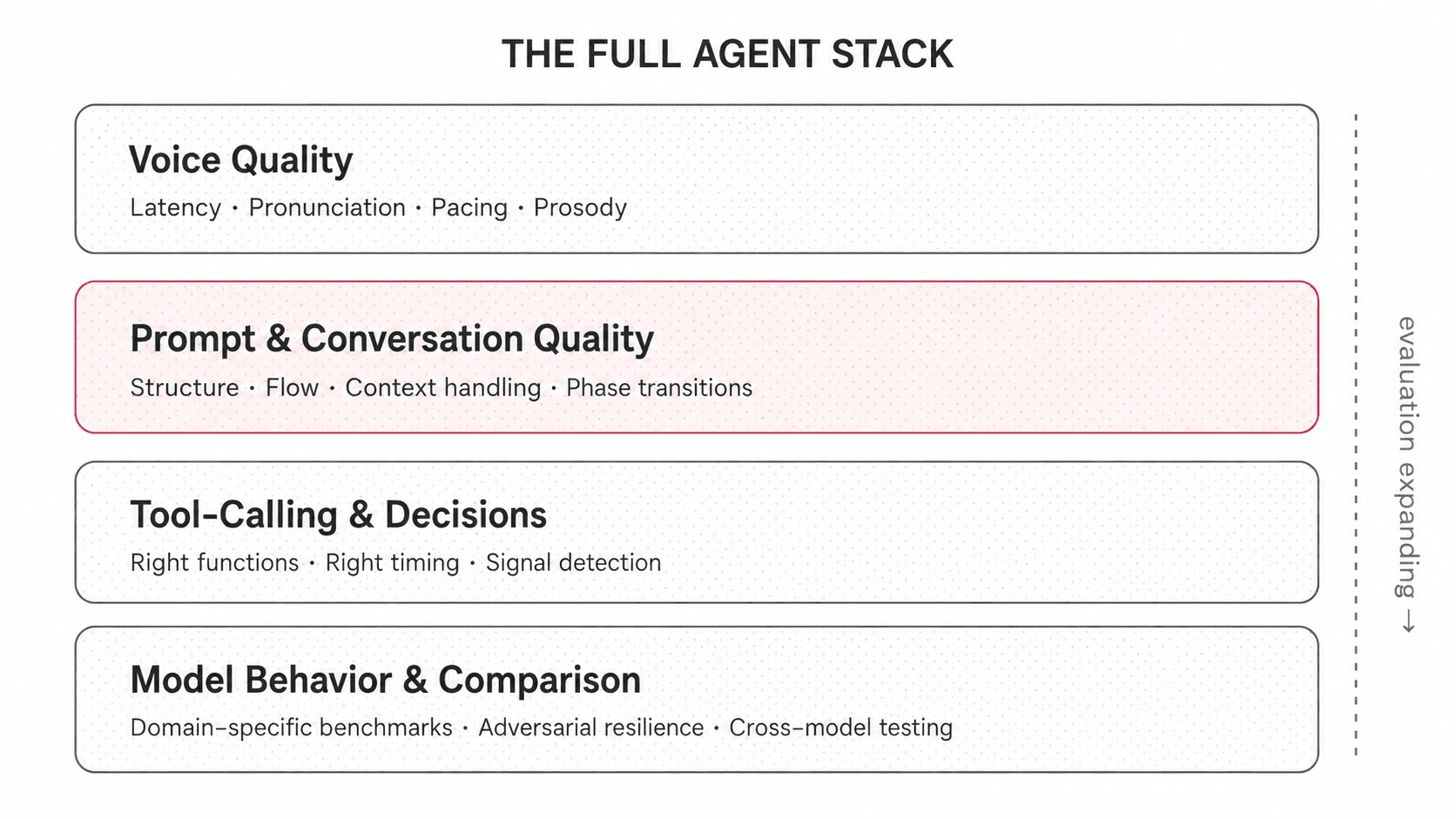
Model comparison. Given the same configuration, how do different models perform, and on which types of conversations? General benchmarks don't predict domain-specific performance. The harness is expanding to support model comparisons: same personas, same metrics, different models to make these decisions empirical rather than intuitive.
Voice quality. How the agent sounds matters independently of what it says. Latency, pronunciation, pacing, prosody; each is a separate quality dimension that can fail independently. A voice agent that pauses too long breaks conversational flow. One that sounds cheerful delivering a past-due notice erodes trust. These need their own evaluation layer.
Continuous monitoring. Today, evaluation runs in batches. The direction is real-time: sample production conversations as they happen, detect regressions immediately. Treat evaluation as an observability concern, not just a pre-ship gate.
Production observability
Voice agents need observability that goes beyond standard uptime monitoring. A system can show green on every infrastructure metric while conversations are silently degrading. The metrics that matter span the full pipeline:
Latency: end-to-end response time, LLM time-to-first-token, TTS generation delay, P95 and P99 percentiles (not just averages)
Conversation quality: task completion rates, escalation frequency, call drop-off points, turn counts per resolution
Audio and transcription: word error rates, interruption patterns, silence gaps, background noise impact
Business outcomes: conversion rates, resolution rates, repeat call frequency, outcome clarity scores
These feed into dashboards that surface regressions the moment they start, not days later when a client flags them. Per-session tracing links every turn and LLM response under a single session ID for complete visibility into what happened and why. Alerts fire on sustained P95 degradation or outcome drops, not transient spikes.
——————
Where this is going
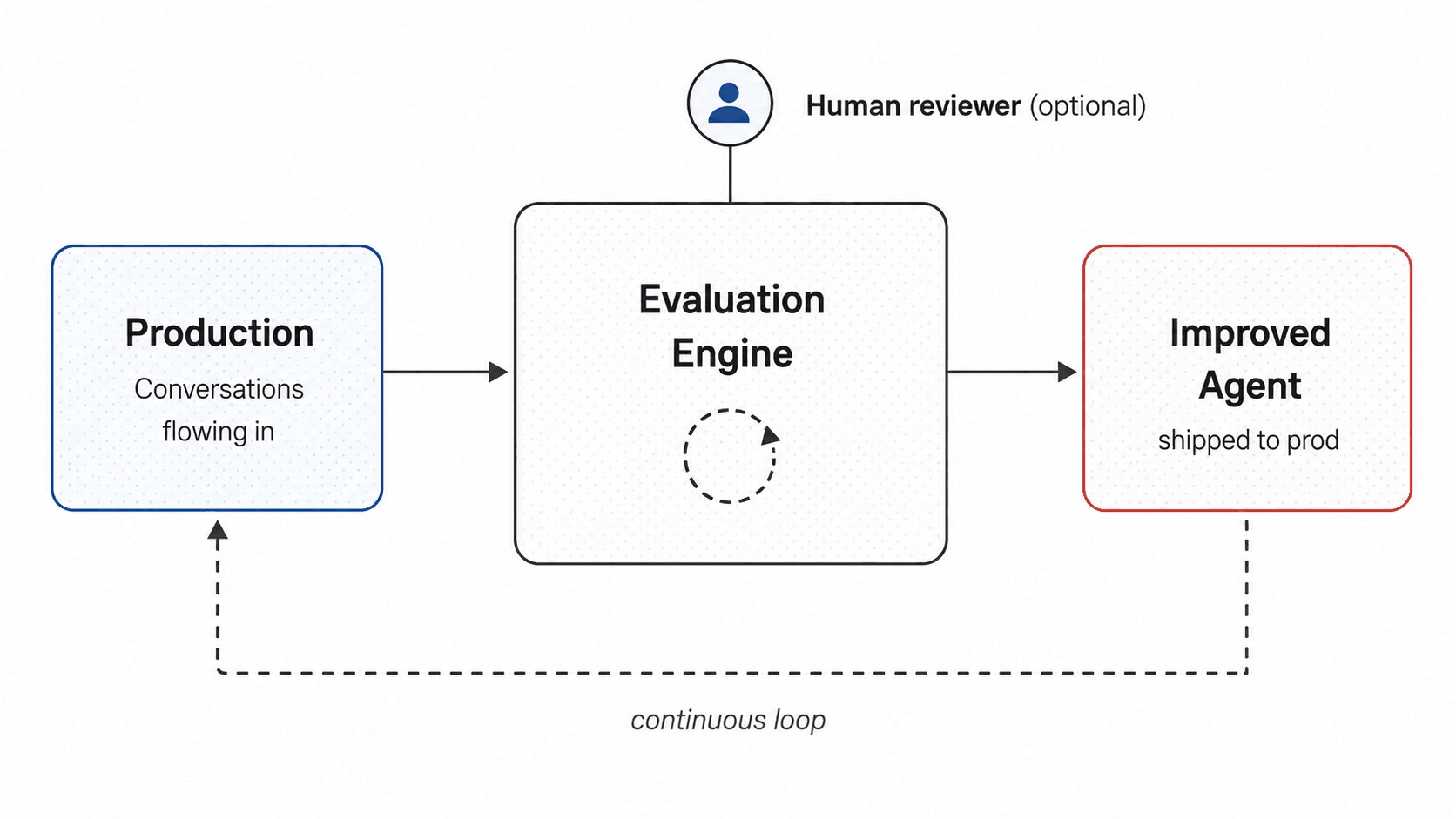
The system today finds patterns in agent behaviour, generates fixes, and tests them before they ship. It surfaces issues we didn't know to look for: patterns that are systemic across calls but invisible in any single transcript.
The direction: a system that monitors the entire agent stack: conversations, model behaviour, voice quality. It discovers problems, generates prompt fixes, validates them in simulation and ships improvements continuously.
————-
References
Anthropic. (2026). Demystifying evals for AI agents. Engineering at Anthropic.
Shankar, S., & Husain, H. (2025). Application-Centric AI Evals for Engineers and Technical Product Managers. AI Evals Course Reader.
OpenAI. (2025). Evaluation Flywheel. OpenAI Cookbook.
OpenAI. (2025). Realtime Eval Guide: Evaluating Voice AI Systems. OpenAI Cookbook.
Riverline handles thousands of debt resolution conversations every day across multiple languages, borrower profiles and fintech portfolios. Each conversation is a voice agent navigating a high-stakes interaction: understanding a borrower's situation, responding to objections, calling the right tools at the right time and reaching a clear outcome.
At thousands of calls a day, you can't listen to everything. Agents break in ways nobody notices. An agent starts repeating itself, a phase transition fails for a specific borrower profile, a change that fixed one scenario quietly breaks another. By the time someone flags it, the pattern has been running across hundreds of conversations. We built a system that finds these problems, generates fixes in prompt and validates them in simulation before they reach production.
System architecture
The system has four layers, each solving a distinct problem:
Layer | Purpose |
|---|---|
Evaluator | Identifies what's going wrong in production |
Improver | Generates targeted agent changes with evidence |
Patcher | Applies scoped edits that preserve what's working |
Harness | Tests fixes in simulation before they ship |
These layers form a closed loop:
The output of this loop isn't a report or a dashboard. It's a specific, proposed prompt change backed by evidence from production and tested in simulation.
The architecture is progressing towards a self-improving agent-prompt loop: a system that autonomously discovers problems, generates fixes in prompt, validates them and ships improvements continuously. The key constraint is guardrails. Automated improvement without boundaries is dangerous, so every layer in the loop operates within defined safety constraints: the evaluator flags only validated failure patterns, the improver generates changes within scoped boundaries, the patcher enforces preservation rules and the harness gates deployment behind regression thresholds. The goal is not unsupervised autonomy but a system that does the cognitive work at scale while staying grounded in measurable, auditable constraints.
The Evaluator
Most evaluation systems output a score. A score tells you how bad things are but not why. Without the why, you can't generate a fix.
The evaluator produces written analysis. Not numbers. For each transcript, it identifies what went wrong, at which turn and how it affected the rest of the conversation. These per-transcript analyses get consolidated across hundreds of calls to surface systemic patterns rather than one-off mistakes.
The evaluator grades each transcript with reasoning, scoring and evidence. What went wrong, where and how it affected the outcome.
Context-awareness
Not every surface-level issue is a real failure. The evaluator has to distinguish genuine problems from appropriate agent behaviour given the conversational context. Otherwise it generates fixes for things that aren't broken.
———
Tuning the judge
Most evaluation datasets are imbalanced. It passes heavily outnumber failures. This makes raw accuracy misleading. A judge that defaults to "pass" on every transcript might hit 95% accuracy while catching zero actual problems.
An evaluator is only useful if its judgments are trustworthy. If the judge says a call failed when it didn't. Or worse, says it passed when it didn't Every downstream decision is wrong. False improvements are more dangerous than no improvements. You ship a change, the judge says it helped, but the actual conversations got worse.
This is why the evaluator itself has to be evaluated Against human judgment.
True Positive Rate (TPR): How well does the judge correctly identify the failures?
True Negative Rate (TNR): How well does the judge correctly identify the passes?
The goal is to achieve high scores on both TPR and TNR. This confirms the judge is effective at finding real problems without being overly critical. This measurement process uses a standard dataset split mentioned below.
Ground truth
The foundation is a golden dataset: a set of transcripts where humans have annotated what actually happened. Did the agent repeat itself unprompted, or was it responding to a legitimate re-ask? Did the call reach a conclusive outcome, or did it drift? These human labels become the source of truth that the judge is measured against.
Building this dataset is deliberate. You start small: annotate a few hundred transcripts across the failure modes you care about, and expand as the system matures.
Dataset splits
The golden dataset serves three distinct purposes, so it gets split accordingly:
Split | Size | Purpose |
|---|---|---|
Fewshots | ~20% | Teach the judge: these examples are embedded as in-context learning for the evaluator |
Validation | ~40% | Iterate and improve: compare judge output against human labels, find disagreements, refine |
Test | ~40% | Final check: held out to verify the judge isn't overfitting to the validation set |
The fewshot split teaches the judge what good and bad looks like. The validation split is where the real work happens: you run the judge, compare its labels against the human annotations and identify where it disagrees. The test split is the honest check at the end.
Aligning the judge
The judge gets measured the same way you'd measure any classifier: precision and recall, tracked against human annotations.
A judge that always says "pass" might look accurate when failures are rare, but it will never surface a single problem. Tracking these metrics against the golden dataset ensures the judge is genuinely aligned with human assessment, not just statistically accurate on an imbalanced distribution.
The tuning cycle: run the judge on the validation set → compare against human labels → identify disagreement patterns → refine the evaluator → re-run. This continues until the judge's precision and recall are stable across the test set.
The entire improvement pipeline downstream (the improver, the patcher, simulation testing) depends on the evaluator's findings being real. If the judge is miscalibrated, every fix it generates addresses a phantom problem or misses an actual one. Tuning the judge is the prerequisite for everything else.
Better judge → better metrics → better improvements → better conversations → more conclusive calls
————-
The evaluation flywheel
With a tuned judge and ground truth in place, the system operates as a continuous flywheel:
Voice agents at scale feel brittle. A configuration that handles conversations well one week can produce unexpected failures the next. Conversations are sensitive to small changes in borrower behaviour, context and phrasing. To build reliable voice agents, you need a systematic way to make them more resilient.
The solution is a continuous, iterative process: the evaluation flywheel. Instead of guessing what might improve an agent, this provides a structured engineering discipline to diagnose, measure and fix problems.
The flywheel consists of three phases:
Analyze: Understand how and why the agent is failing through qualitative review. Examine and annotate transcripts where the agent behaves incorrectly to identify recurring failure modes. The goal is identifying recurring failure patterns, not isolated incidents.
Measure: Turn those qualitative findings into quantifiable metrics. Build a test dataset, define automated graders and establish a baseline. You can't improve what you can't measure.
Improve: Apply targeted fixes, including modifying agent behaviour, restructuring conversation phases, adding edge-case handling. Because measurement is already in place, the impact of each change is visible immediately.
The cycle never finishes and is continuous. Every round of improvements raises the bar, and previously invisible failure modes surface. The agent gets better not through intuition but through compounding, measurable iterations.
The Improver and Patcher
The evaluator's findings feed into two downstream layers. The improver generates targeted modification proposals, each tied to a specific conversation phase and backed by evidence from real calls. The patcher applies those modifications with a key constraint: changes must be scoped and traceable. Not full rewrites, but targeted edits that preserve everything already working. This ensures traceability when something regresses, preservation of configurations earned through months of production and the ability to roll back individual changes without affecting unrelated improvements.
—————
The Harness
Evaluation tells you what went wrong in the past. The harness tells you whether a fix actually helps, before it touches production.
The harness runs LLM-vs-LLM simulations: one LLM plays the agent with the actual agent configuration, another plays a borrower persona.
Composable personas
Scripted test cases don't capture the diversity of real conversations. A persona-based approach does: each simulated borrower is assembled from three independent layers:
Each layer is independent. Any profile can combine with any communication style and any behaviour pattern. This generates a wide range of realistic test personas from a small number of well-defined traits.
Scaling through composition
The composable approach is what makes this scale. Instead of hand-writing hundreds of test scripts, you define traits per layer and let the combinations multiply:
8 profiles × 6 communication styles × 10 behaviour patterns × 3 languages = 1,440 distinct test personas
This is combinatorial coverage, not brute force. A small number of well-chosen traits per layer generates a large, diverse test surface. And it scales further. Adding one new behaviour pattern creates new test cases across every profile and language without duplicating work.
From small to production scale
You don't start with all 1,440. The system grows progressively, optimising the prompts and improving the voice agent.
The important thing isn't the number; it's that results are tracked per persona, not in aggregate. An agent that scores well on average but consistently fails with evasive Hindi-speaking borrowers has a real problem that aggregate metrics would hide.
Regression testing
Every agent version must pass through the regression set before it ships. If a modification introduces a new failure, even for a single persona, it gets caught in simulation rather than production. This is a fixed set of personas against which any prompt must be optimised for.
—————
Expanding towards a robust eval system
Everything above is focused on conversation quality – that's where the system operates today. But a voice AI agent is several systems working together, each with its own failure modes. We're expanding the same evaluate-improve-test loop across the full stack.
Model comparison. Given the same configuration, how do different models perform, and on which types of conversations? General benchmarks don't predict domain-specific performance. The harness is expanding to support model comparisons: same personas, same metrics, different models to make these decisions empirical rather than intuitive.
Voice quality. How the agent sounds matters independently of what it says. Latency, pronunciation, pacing, prosody; each is a separate quality dimension that can fail independently. A voice agent that pauses too long breaks conversational flow. One that sounds cheerful delivering a past-due notice erodes trust. These need their own evaluation layer.
Continuous monitoring. Today, evaluation runs in batches. The direction is real-time: sample production conversations as they happen, detect regressions immediately. Treat evaluation as an observability concern, not just a pre-ship gate.
Production observability
Voice agents need observability that goes beyond standard uptime monitoring. A system can show green on every infrastructure metric while conversations are silently degrading. The metrics that matter span the full pipeline:
Latency: end-to-end response time, LLM time-to-first-token, TTS generation delay, P95 and P99 percentiles (not just averages)
Conversation quality: task completion rates, escalation frequency, call drop-off points, turn counts per resolution
Audio and transcription: word error rates, interruption patterns, silence gaps, background noise impact
Business outcomes: conversion rates, resolution rates, repeat call frequency, outcome clarity scores
These feed into dashboards that surface regressions the moment they start, not days later when a client flags them. Per-session tracing links every turn and LLM response under a single session ID for complete visibility into what happened and why. Alerts fire on sustained P95 degradation or outcome drops, not transient spikes.
——————
Where this is going
The system today finds patterns in agent behaviour, generates fixes, and tests them before they ship. It surfaces issues we didn't know to look for: patterns that are systemic across calls but invisible in any single transcript.
The direction: a system that monitors the entire agent stack: conversations, model behaviour, voice quality. It discovers problems, generates prompt fixes, validates them in simulation and ships improvements continuously.
————-
References
Anthropic. (2026). Demystifying evals for AI agents. Engineering at Anthropic.
Shankar, S., & Husain, H. (2025). Application-Centric AI Evals for Engineers and Technical Product Managers. AI Evals Course Reader.
OpenAI. (2025). Evaluation Flywheel. OpenAI Cookbook.
OpenAI. (2025). Realtime Eval Guide: Evaluating Voice AI Systems. OpenAI Cookbook.