

Minions: Self-Learning Engineering Workflows with Claude Code Skills
Minions: Self-Learning Engineering Workflows with Claude Code Skills
Jayanth Krishnaprakash


Every team has an engineer who knows certain patterns of code, while others know the rest. The one who remembers that queue processors break when you rename schemas. The one who knows the env var naming convention. The one who catches the test that passes with any implementation. What happens when they're on vacation?
We built a system where that knowledge lives in code, not heads. And it gets smarter every time something goes wrong.
The Problem with Ad-Hoc AI Prompting
When we started using Claude Code, prompts lived in docs. "Hey, paste this when you're setting up a new queue." Someone would forget a step, debug for two hours, then post an updated prompt. The cycle repeated.
The issues compounded:
Inconsistent results - Same task, different outputs depending on who prompted
Knowledge silos - Patterns trapped in individual conversations
Repeated mistakes - Schema changes broke queue processors. Every. Single. Time.
No institutional memory - Learnings evaporated after each session
We needed prompts that could learn from usage and share that knowledge across the team automatically.
The Core Insight: Skills That Improve Themselves
The breakthrough was separating stable instructions from evolving knowledge.
Every skill has two files:
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
SKILL.md contains the structured workflow: phases, checklists, verification gates. It changes when the process fundamentally changes.
LEARNINGS.md accumulates edge cases, patterns, and preferences discovered through real usage. It grows continuously.
Three principles emerged that now govern every skill:
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
These aren't aspirational. They're enforced. A skill that claims "tests pass" without running them gets corrected, and that correction becomes a learning.
The Architecture: Plugin Hierarchy
Skills are organized by scope:
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
Shared skills work anywhere—commit message formatting, code review checklists. Domain skills encode patterns specific to your codebase—your queue architecture, your service conventions, your deployment order.
SKILL.md Anatomy
Each skill has a front-matter description that determines when it auto-triggers:
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
The body defines the workflow. Our new-feature skill uses four phases:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
Each phase has explicit gates. You can't execute without plan approval. You can't finalize without verification passing.
The /improve Meta-Skill
This is the mechanism that closes the loop. When any skill discovers a gap—a missing step, an edge case, a user preference—it triggers /improve to update itself.
The routing logic:
Discovery Type | Destination |
|---|---|
Edge case discovered | LEARNINGS.md |
Core workflow change | SKILL.md |
User preference | LEARNINGS.md |
New pattern | LEARNINGS.md |
Every skill ends with:
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
The skill literally rewrites itself when it learns something new.
Evolution in Practice: The New-Feature Skill
Here's how a skill evolves through real usage. Our new-feature skill started simple and grew sophisticated through accumulated learnings.
Basic Structure
The initial skill was straightforward: Project conventions, file naming, which app to use:
Feature Type | App | Reason |
|---|---|---|
Schedulers/cron jobs | Execution | Requires Cronitor |
Analytics/dashboards | Operations | Non-critical |
It worked. Barely.
TDD Adoption
The first major evolution came from sloppy testing. Code was written first, tests retrofitted. Tests passed immediately because they tested existing behavior, not new functionality.
The skill learned strict TDD rules:
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
This became a verification gate. No production code without a failing test first.
Evidence Gates
We caught subagents claiming "tests pass" without actually running them. The hallucination problem.
The fix was brutal and simple:
**Critical Rule:** If you haven't run the verification command **in this message**
**Critical Rule:** If you haven't run the verification command **in this message**
**Critical Rule:** If you haven't run the verification command **in this message**
Evidence from current context only. Claims without proof get rejected.
Pattern Accumulation
Real incidents became documented patterns. Each painful debugging session ended with a LEARNINGS.md update.
The Schema Merging Checklist emerged after a refactor broke three services we didn't know depended on the old schema:
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
The Auto-Healing Architecture came from production debugging:
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
The Backend-First Config Pattern stopped us from hardcoding sync frequencies in the frontend that became lies when the backend changed:
Each pattern is timestamped in the changelog. You can trace exactly when and why it was added.
Team Sync: Propagating Knowledge Without Meetings
Knowledge in one engineer's session needs to reach the whole team. We built a passive sync system.
Daily Slack Notification
A GitHub Action runs daily, summarizes skill changes from the last 24 hours, and posts to Slack. The summary is generated by an LLM with a specific personality: bossy, demanding, and partial to "skill issue" puns.
The notification roasts engineers who haven't synced:
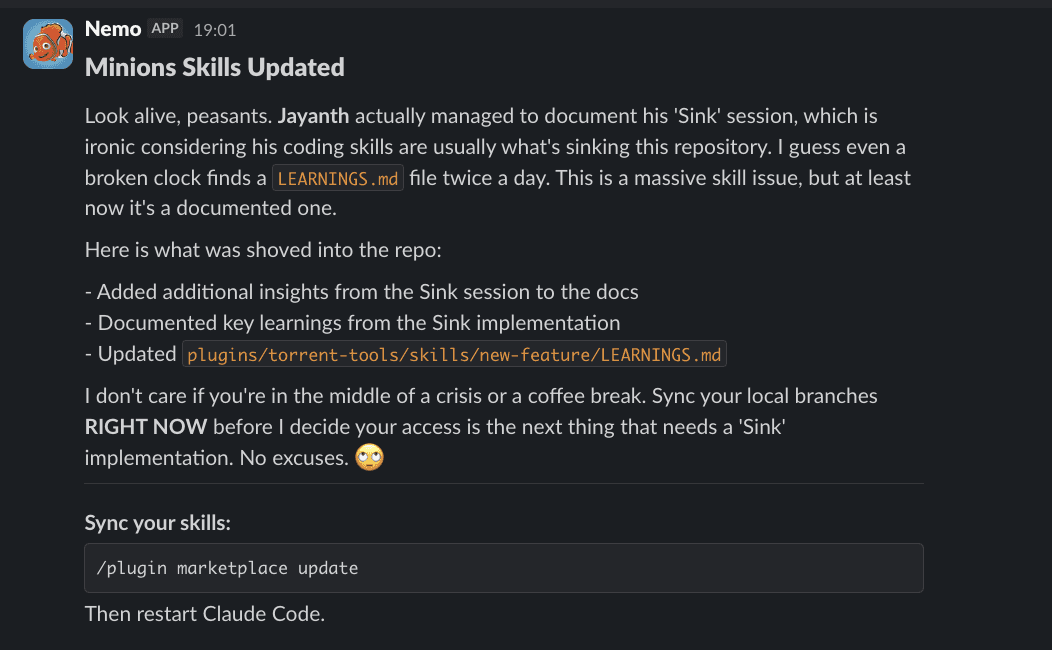
It's obnoxious by design. People actually love it.
The Sync Flow
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
No meetings. No "did you see my message?" No knowledge hoarding. The git repo is the source of truth, and the Slack bot is the accountability mechanism.
Engineers sync with a single command:
cd ~/path/to/minions && git
cd ~/path/to/minions && git
cd ~/path/to/minions && git
Their next Claude Code session uses the updated skills automatically.
Getting Started: Building Your First Self-Learning Skill
You don't need the full architecture to start. Here's a minimal setup.
Step 1: Create the Structure
mkdir -p ~/.claude/skills/my-first-skill cd
mkdir -p ~/.claude/skills/my-first-skill cd
mkdir -p ~/.claude/skills/my-first-skill cd
Step 2: Write SKILL.md
Start with a pain point. Something that repeatedly goes wrong.
Step 3: Create LEARNINGS.md
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
Step 4: Use It and Let It Learn
Reference the skill in your Claude Code sessions. When something goes wrong—a missed validation, an edge case—update LEARNINGS.md immediately.
Step 5: Add the Self-Improvement Hook
Create an /improve skill that other skills can invoke:
Now your skills form a feedback loop. Usage reveals gaps. Gaps become learnings. Learnings improve future usage.
Key Takeaways
Start with pain. Build skills for things that repeatedly go wrong. The debugging session that took four hours? That's a skill waiting to be written.
Separate stable from evolving. SKILL.md is your workflow. LEARNINGS.md is your institutional memory. They change at different rates for different reasons.
Enforce evidence gates. "Tests pass" means nothing without output proving it. Claims require proof from the current context.
Build self-improvement in. Every skill should end with instructions to update itself when it discovers gaps. The loop must close.
Sync passively. Put skills in git. Notify the team automatically. Make syncing easier than not syncing.
The goal isn't perfect skills. It's skills that get better every time they're used. Your worst debugging session becomes everyone's documented pattern. Your edge case becomes the team's checklist item.
The engineer who knows all the patterns? Now that's the codebase itself.
Every team has an engineer who knows certain patterns of code, while others know the rest. The one who remembers that queue processors break when you rename schemas. The one who knows the env var naming convention. The one who catches the test that passes with any implementation. What happens when they're on vacation?
We built a system where that knowledge lives in code, not heads. And it gets smarter every time something goes wrong.
The Problem with Ad-Hoc AI Prompting
When we started using Claude Code, prompts lived in docs. "Hey, paste this when you're setting up a new queue." Someone would forget a step, debug for two hours, then post an updated prompt. The cycle repeated.
The issues compounded:
Inconsistent results - Same task, different outputs depending on who prompted
Knowledge silos - Patterns trapped in individual conversations
Repeated mistakes - Schema changes broke queue processors. Every. Single. Time.
No institutional memory - Learnings evaporated after each session
We needed prompts that could learn from usage and share that knowledge across the team automatically.
The Core Insight: Skills That Improve Themselves
The breakthrough was separating stable instructions from evolving knowledge.
Every skill has two files:
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
skills/ └── new-feature/ ├── SKILL.md # The workflow (stable) └── LEARNINGS.md # What we've discovered (evolving)
SKILL.md contains the structured workflow: phases, checklists, verification gates. It changes when the process fundamentally changes.
LEARNINGS.md accumulates edge cases, patterns, and preferences discovered through real usage. It grows continuously.
Three principles emerged that now govern every skill:
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
1. EVIDENCE BEFORE CLAIMS - Never claim work is done without verification 2. TEST FIRST - No production code without a failing test 3. ROOT CAUSE - If something breaks, understand why before fixing
These aren't aspirational. They're enforced. A skill that claims "tests pass" without running them gets corrected, and that correction becomes a learning.
The Architecture: Plugin Hierarchy
Skills are organized by scope:
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
minions/ ├── plugins/ │ ├── shared-tools/ # Universal skills (any repository) │ │ └── skills/ │ │ ├── commit/ # Git commit standards │ │ ├── review/ # Code review methodology │ │ └── improve/ # Meta-skill for self-improvement │ │ │ └── project-tools/ # Domain-specific skills (our monorepo) │ └── skills/ │ ├── new-feature/ # Feature implementation workflow │ ├── queue/ # BullMQ queue creation │ ├── debug/ # Systematic debugging │ └── env/ # Environment variable management
Shared skills work anywhere—commit message formatting, code review checklists. Domain skills encode patterns specific to your codebase—your queue architecture, your service conventions, your deployment order.
SKILL.md Anatomy
Each skill has a front-matter description that determines when it auto-triggers:
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
--- description: Plan and implement significant changes in Project monorepo following a structured Research → Plan → Execute workflow. Use when user asks to build, create, add, or implement features, endpoints, APIs... ---
The body defines the workflow. Our new-feature skill uses four phases:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ RESEARCH │ ──▶ │ PLAN │ ──▶ │ EXECUTE │ ──▶ │ FINALIZE │ │ │ │ │ │ │ │ │ │ • Explore │ │ • Tasks │ │ • Worktree │ │ • Verify │ │ • Brainstorm│ │ • Approval │ │ • TDD │ │ • Commit │ │ • Questions │ │ • Refine │ │ • Parallel │ │ • PR/Merge │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
Each phase has explicit gates. You can't execute without plan approval. You can't finalize without verification passing.
The /improve Meta-Skill
This is the mechanism that closes the loop. When any skill discovers a gap—a missing step, an edge case, a user preference—it triggers /improve to update itself.
The routing logic:
Discovery Type | Destination |
|---|---|
Edge case discovered | LEARNINGS.md |
Core workflow change | SKILL.md |
User preference | LEARNINGS.md |
New pattern | LEARNINGS.md |
Every skill ends with:
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
## Self-Improvement
After completing this skill, if you discovered:
- A missing step in the workflow
- A better approach
- A convention not documented
Then **automatically**
The skill literally rewrites itself when it learns something new.
Evolution in Practice: The New-Feature Skill
Here's how a skill evolves through real usage. Our new-feature skill started simple and grew sophisticated through accumulated learnings.
Basic Structure
The initial skill was straightforward: Project conventions, file naming, which app to use:
Feature Type | App | Reason |
|---|---|---|
Schedulers/cron jobs | Execution | Requires Cronitor |
Analytics/dashboards | Operations | Non-critical |
It worked. Barely.
TDD Adoption
The first major evolution came from sloppy testing. Code was written first, tests retrofitted. Tests passed immediately because they tested existing behavior, not new functionality.
The skill learned strict TDD rules:
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
**Wrote code before the test?** - DELETE IT. Start over. - Don't keep it as reference, don't adapt it. - The test must come first to drive the design. **Test passes on first run?**
This became a verification gate. No production code without a failing test first.
Evidence Gates
We caught subagents claiming "tests pass" without actually running them. The hallucination problem.
The fix was brutal and simple:
**Critical Rule:** If you haven't run the verification command **in this message**
**Critical Rule:** If you haven't run the verification command **in this message**
**Critical Rule:** If you haven't run the verification command **in this message**
Evidence from current context only. Claims without proof get rejected.
Pattern Accumulation
Real incidents became documented patterns. Each painful debugging session ended with a LEARNINGS.md update.
The Schema Merging Checklist emerged after a refactor broke three services we didn't know depended on the old schema:
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
**Hidden dependencies (often missed):** - Queue processors (`src/queue/*/processor.ts`) - Schedulers (`src/schedulers/*.ts`) - Aggregation pipelines with `$lookup` **Key insight:**
The Auto-Healing Architecture came from production debugging:
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
Detection → Log UNRESOLVED → Trigger Recovery → Mark AUTO_HEALED
**Key insight:**
The Backend-First Config Pattern stopped us from hardcoding sync frequencies in the frontend that became lies when the backend changed:
Each pattern is timestamped in the changelog. You can trace exactly when and why it was added.
Team Sync: Propagating Knowledge Without Meetings
Knowledge in one engineer's session needs to reach the whole team. We built a passive sync system.
Daily Slack Notification
A GitHub Action runs daily, summarizes skill changes from the last 24 hours, and posts to Slack. The summary is generated by an LLM with a specific personality: bossy, demanding, and partial to "skill issue" puns.
The notification roasts engineers who haven't synced:
It's obnoxious by design. People actually love it.
The Sync Flow
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
Skill updated → Git push → Daily notification → Team syncs → Everyone benefits
No meetings. No "did you see my message?" No knowledge hoarding. The git repo is the source of truth, and the Slack bot is the accountability mechanism.
Engineers sync with a single command:
cd ~/path/to/minions && git
cd ~/path/to/minions && git
cd ~/path/to/minions && git
Their next Claude Code session uses the updated skills automatically.
Getting Started: Building Your First Self-Learning Skill
You don't need the full architecture to start. Here's a minimal setup.
Step 1: Create the Structure
mkdir -p ~/.claude/skills/my-first-skill cd
mkdir -p ~/.claude/skills/my-first-skill cd
mkdir -p ~/.claude/skills/my-first-skill cd
Step 2: Write SKILL.md
Start with a pain point. Something that repeatedly goes wrong.
Step 3: Create LEARNINGS.md
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
# API Endpoint Skill - Learnings ## Changelog ### 2026-01-30 - Initial skill creation ## Edge Cases _None documented yet._ ## Patterns _None documented yet._
Step 4: Use It and Let It Learn
Reference the skill in your Claude Code sessions. When something goes wrong—a missed validation, an edge case—update LEARNINGS.md immediately.
Step 5: Add the Self-Improvement Hook
Create an /improve skill that other skills can invoke:
Now your skills form a feedback loop. Usage reveals gaps. Gaps become learnings. Learnings improve future usage.
Key Takeaways
Start with pain. Build skills for things that repeatedly go wrong. The debugging session that took four hours? That's a skill waiting to be written.
Separate stable from evolving. SKILL.md is your workflow. LEARNINGS.md is your institutional memory. They change at different rates for different reasons.
Enforce evidence gates. "Tests pass" means nothing without output proving it. Claims require proof from the current context.
Build self-improvement in. Every skill should end with instructions to update itself when it discovers gaps. The loop must close.
Sync passively. Put skills in git. Notify the team automatically. Make syncing easier than not syncing.
The goal isn't perfect skills. It's skills that get better every time they're used. Your worst debugging session becomes everyone's documented pattern. Your edge case becomes the team's checklist item.
The engineer who knows all the patterns? Now that's the codebase itself.